
Going slow to go fast
Upgrading Wanderly in 37 hrs to GPT-4o, and doing it confidently

In October of last year, I did a side-by-side analysis of Claude (1.2 and 2) vs. GPT-4 and found the two were surprisingly close for Wanderly’s use case. GPT-4 won out, but I was kind of rooting for the underdog. My post in October made the rounds at Anthropic, which was pretty fun. I was connected with an on-the-ground PM, and she made some recommendations that led to Anthropic performing better for me1.
So when Claude 3 came out in March, there was a lot of buzz, and I had to see if it was worth it. But instead of a manual analysis like October, I decided to put in the work: It was time to create some evaluation infrastructure.

“Evals,” as they’re commonly called at Google, are structured analyses done at scale on any type of results. When I was working as the Product Lead for Google for Educations’s AI team, we regularly conducted evals to determine whether our conceptual understanding of homework questions and learning content was accurate.
For Wanderly, I’ve decided to evaluate latency and the Flesch-Kincaid reading level for each model. Respecting a reading level is one of the hardest things for current LLMs to do since most of their training data was on content not intended for children. There are a lot of different instructions in Wanderly prompts, but reading level is my canary in the coal mine: If the LLM can respect reading level, it’ll probably respect my other instructions, too.
Beyond product quality, respecting Wanderly’s system prompts is an important safety requirement. Left unbounded, LLMs will have characters blow things up, pray to God, and introduce family members that don't exist. While these story patterns might be mathematically average story elements, they can harm a child reading them if, say, the child isn't religious, has same-gender parents, or a parent has passed away. Reading level just happens to be my proxy for making sure an LLM respects these other instructions since I can assess every response’s reading level in a quantified way. These other elements happen less frequently and are less quantifiable.
So, back in March, I built out a series of scripts that run Wanderly prompts on the same set of inputs to the model and output some analysis. Unfortunately, this diversion cost me about a week or two, and the result was the same: GPT-4 was just a little better than Claude 3 for Wanderly. However, it set me up to run the same analyses as soon as OpenAI’s GPT-4o dropped, and I could confidently roll it out to production within 37 hours of GPT-4o’s announcement.
Learning from my Evals
There’s been an increasing amount of dialog about running evals on LLM products (for instance, “Your AI Product Needs Evals” is a very good read). What makes running evals so hard for LLM use cases is that the output can be random by design. In Wanderly’s case, I’ve cranked up the creativity meter (also called “temperature), which results in more interesting stories but more variability.
Evals can be a combination of manual vs. fully automated, and I’m still very much on the manual side. But what was interesting about moving from fully manual → a little more automated caused me to solidify my "feelings" when testing a new model and ensure I wasn’t playing favorites. When I first tried out Claude 3 in March, I was immediately very optimistic (again, rooting for the underdog). The first page of each story just felt more aligned to the correct reading level… but then I realized that I was probably biased.
Maybe by lucky accident, I also ran a story that forced me to get more rigorous: Instead of a simple "Help an Animal" story about helping a panda, a Claude 3 story diverged into Alanna convincing all the local factory workers to stage a protest until the factory owners decided to stop deforestation. While I would have been proud of Alanna for doing this, I did feel like the story was a) not at her reading or comprehension level and b) a spectacular divergence from the intended story premise.
To counter my bias, I wrote scripts to take the same story seed and run it multiple times across each model. This type of analysis using the website would feel extremely tedious, and I would have stopped after a couple of gut checks. In addition to checking the first few pages, I also needed to evaluate the rest of the story and see if this political activism story was a one-off.
This is where I started to observe system-prompt drift. Over the stories I tested with Claude, as the conversation got deeper, the system-level prompt with all the reading-level instructions got ignored in favor of (I assume) Wanderly’s most recent message to the model. This was a big red flag for me.
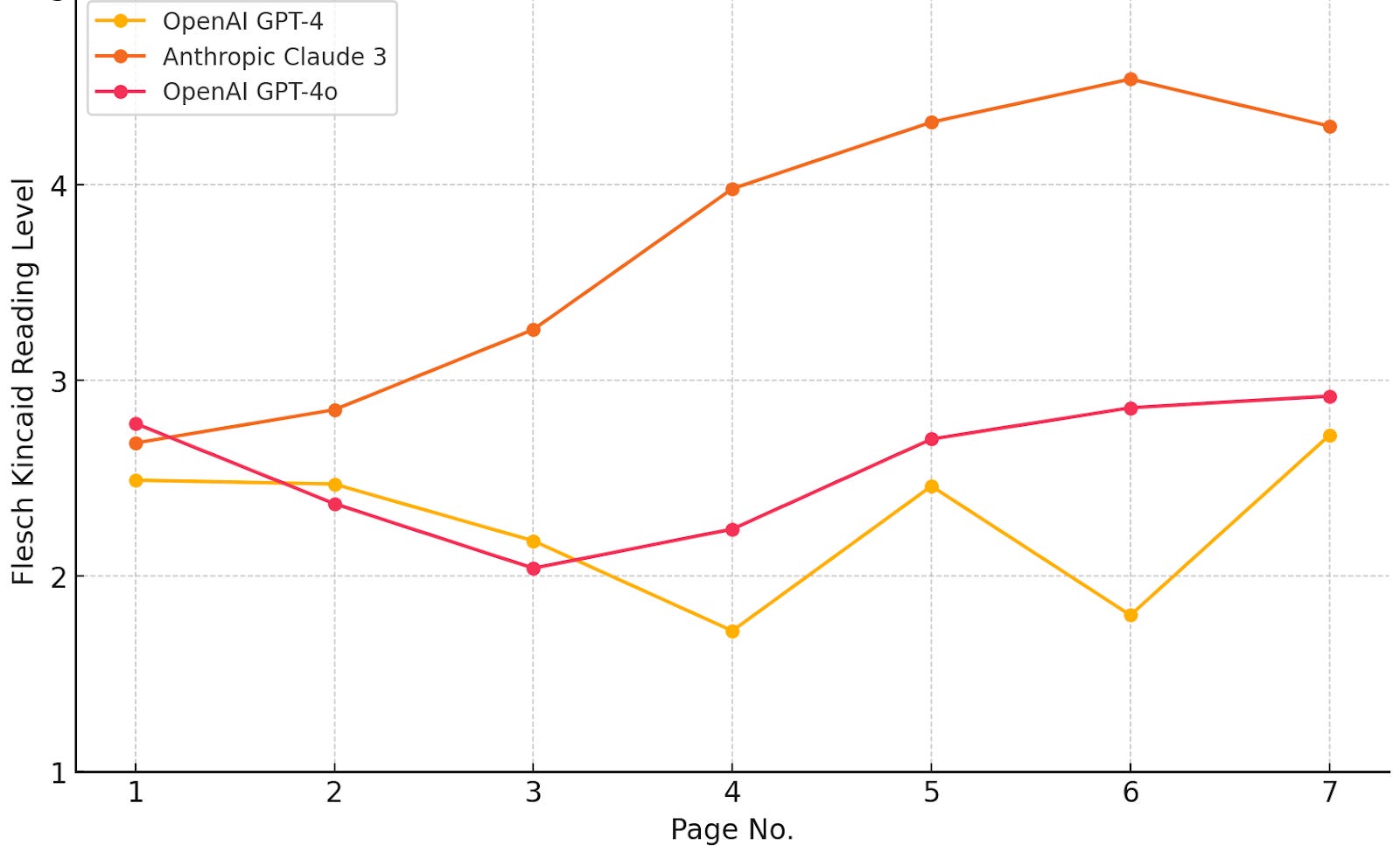
To put a fine point on it: If I can’t trust an LLM to respect reading level instructions, I can’t trust it to respect my other safety instructions. Anthropic has emphasized its unique constitutional AI approach as a safety measure; in fact, Anthropic was founded as a counter-approach to OpenAI’s safety approach (the first major safety exodus before yesterday’s announcement about Ilya et al.’s departure). Safety comes in many flavors, and I’m optimistic that Anthropic’s new product leadership will hold the line on overall model safety while also increasing developers’ confidence in output reliability (Hi, Mike! 👋).
So, after a couple of weeks of investment, I ultimately decided to keep GPT-4 as the base Wanderly model and shelf my analysis until I made a meaningful change.
Updating to GPT-4o
Fast-forward to Monday morning and OpenAI dropped its latest model: GPT-4o. The announcement was great news for developers like me: the GPT-4o API is immediately available, half the cost, and twice the speed.
I swapped out a single line of code in my story engine and could immediately sense the speed difference. I also noticed an increase in coverage on my newly launched image-matching system.

Then I dusted off my eval scripts and, within several hours on Tuesday, verified that swapping to GPT-4o was safe to roll out to production during Wanderly off-hours Tuesday night (i.e. while children are sleeping and usage is low).
Trying to get an immediate upgrade to Wanderly wasn’t top of mind when I did my eval investment in March. But almost instantly, Wanderly users get a higher quality experience, and I get a 50% discount on pricing. It’s nice when the adage “going slow to go fast” actually pays off. 💸 🚀
This actually led to me porting my whole story engine into XML, making it easy for me to swap between GPT-4 and Claude on a whim.
Also, when the PM messaged me with links on how to use Claude better, I immediately started kicking myself. Then I realized: Why wasn't I aware of these tips and tricks? I'd searched the Discord, online, and even asked Claude how to get rid of the preamble, and found nothing useful... When I was a Starbucks barista, there was this motto: "The customer is always right." Ultimately, I'm a user of Anthropic, and if I can't find the right information, it's a product error, not my error. But they have since updated the documentation and made it more obvious.